注意:当前最新版本5.0,请移驾至底部。
JavaScript版抓取花瓣网、堆糖网,油猴脚本,更方便更快捷,有兴趣请移驾至 https://blog.saintic.com/blog/256.html
################################################################
当前区域版本1.0
代码库:https://github.com/staugur/grab_huaban_board/releases/tag/v1.0
Python抓取花瓣网“画板”的图片,程序稍简陋,后续并发执行(也适用并发)。
发现规律:
1. 画板(board)的title中包含了此画板所有图片(pin),可以获取到关键信息——画板数量。
2. 除了首屏的图片外,往下滚动,动态加载时,采用ajax,F12查看Network,发现请求了画板URL+/?iw538bzd&max=916733010&limit=20&wfl=1,其中max是当前展现的最后一个图片的pin id,limit是ajax刷新后的图片数量。
3. pin的URL是http://huaban.com/pins/+pin,可以查看具体大图,查看其HTML源码,能发现以下信息:
app["page"] = {
"$url": "/pins/939351949/",
"pin": {
"pin_id": 939351949,
"user_id": 9880671,
"board_id": 32956845,
"file_id": 122346806,
"file": {
"bucket": "hbimg",
"key": "591ba6953c5912c9d82272b9cc575fe1b04fbe9919a01-tKc4ku",
"type": "image/jpeg",
"height": "640",
"width": "640",
"frames": "1"
}
}
}
这里的规律是以空格为分割,倒数第八段基本是以上代码开端。
实现思路:
根据两个规律可以查出画板board的所有pin,然后查出pin所对应的Imagekey(图片存储在第三方的一个ID),第三方固定地址:“http://img.hb.aicdn.com/%s_fw658” %Imagekey"。
代码逻辑:
1. 传递“画板ID"参数,可以直接用sys.argv位置参数,我用了内置模块argparse解析选项参数。
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("-b", "--board", help="The board id for Huanban.com", type=int)
args = parser.parse_args()
if args.board:
print GetBoard(args.board)
2. 获取画板参数后,执行GetBoard函数(传递board)。
def GetBoard(board):
代码
以下代码获取画板所有图片数量,title number:
#get title pin number
r = requests.get(url, timeout=15, verify=False, headers=headers)
title_pat = re.compile(r'<title>.*\((\d+).*\).*</title>')
data=r.text.encode('utf-8')
allimages = re.findall(title_pat, data)[0]
以下代码获取首屏图片pins:
#first
url = "http://huaban.com/boards/%s/?limit=%d" %(board, int(limit))
data = requests.get(url, timeout=10, verify=False, headers=headers).text.encode('utf-8')
pins = [ _[-1] for _ in re.findall(pat, data) if _[-1] ]
以下代码不断循环刷新请求,直到获取不到任何pin,则中断:
while not END:
#ajax
url = "http://huaban.com/boards/%s/?max=%s&limit=%s&wfl=1" %(board, pins[-1], limit)
data = requests.get(url, timeout=10, verify=False, headers=headers).text.encode('utf-8')
_pins= [ _[-1] for _ in re.findall(pat, data) if _[-1] ]
print "ajax get %s pins, last pin is %s, merged" %(len(_pins), pins[-1])
_pins= [ _[-1] for _ in re.findall(pat, data) if _[-1] ]
pins += _pins
if len(_pins) == 0:
break
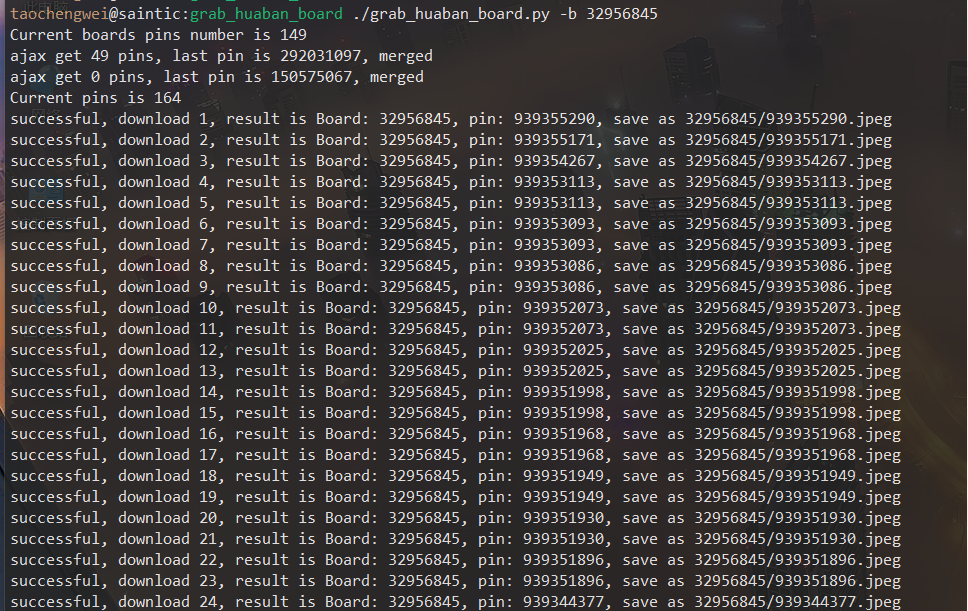
以上步骤获取到所有pin,结果是list,循环此list,下载每个pin图片保存,这里后续改为multiprocessing.dummy多线程并发,当前顺序执行很慢(哎、Python)。
看看效果:
################################################################
当前区域版本2.0
代码库:https://github.com/staugur/grab_huaban_board/releases/tag/v2.0
版本更新至2.0,变化为:
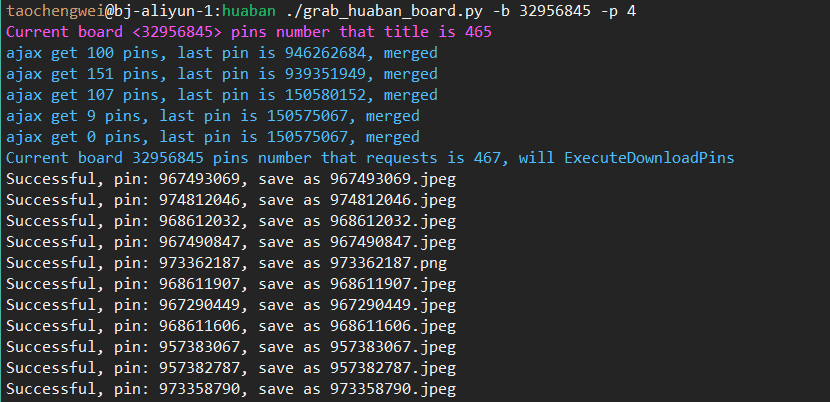
- 1. 获取所有pins,使用multiprocessing.dummy的线程池,线程并发数量可以用-p(–processes)指定,速度大幅度增加;
- 2. 记录日志
################################################################
当前区域版本3.0
代码库:https://github.com/staugur/grab_huaban_board/releases/tag/v3.0
版本更新至3.0,新功能:
- 1. 整体代码调整
- 2. 多画板抓取,每个画板一个进程,每个进程用线程池
################################################################
当前区域版本4.0
代码库:https://github.com/staugur/grab_huaban_board/releases/tag/v4.0
版本更新至4.0,新功能:
- 1. 抓取用户下指定数量(limit)的画板,每个用户开启一个进程,每个用户下每个画板开启子进程,所以limit设置的值切记不要过大,默认10,如果用户有10个以上画板,将只下载10个,开启10个进程,建议不要超过50(根据机器硬件情况)。修改此值,需编辑grab_huaban_board.py,GetUserBoards函数,修改limit默认函数值。
- 2.多用户抓取
################################################################
当前区域版本5.0
代码库:https://github.com/staugur/grab_huaban_board/releases/tag/v5.0
版本更新至5.0,增加了一个油猴脚本,参见https://blog.saintic.com/blog/256.html
当前版本完全重写,原理是模拟ajax请求获取huaban.com返回的JSON数据,并且可以模拟登录,保持session,登录后,抓取图片的数量大部分可达100%。
目前功能如下:
- 1. 抓取单个画板;
- 2. 抓取单个用户所有画板。